Una vez tenemos Raspberry Pi OS funcionando en la Raspberry, el siguiente paso es actualizar el sistema.Para ello, tenemos que tener conectados al miniordenador una pantalla y un teclado, que a partir de este paso, gracias a la magia de SSH, no nos volverán a hacer falta.
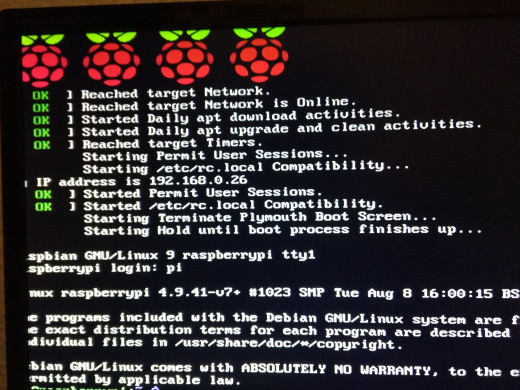
El primer arranque se demora varios minutos. En versiones anteriores no era así, pero creo que se debe a que ahora al arrancar la primera vez se actualiza y prepara varias cosas, pero las veces siguientes no tardará más de unos instantes.
Por si acaso, para actualizar el sistema, los comandos que tenemos que escribir son estos:
sudo apt-get update
Actualiza la información de actualizaciones
sudo apt-get dist-upgrade
Actualiza los paquetes, los programas.
Como Raspberry Pi OS está configurado por defecto en inglés, puedes tener problemas para escribir el guion. Puedes usar el signo menos del teclado numérico y, si no lo tienes, prueba con el apóstrofe, la tecla que hay a la derecha del 0. Aunque esté así, a continuación podremos cambiarlo.
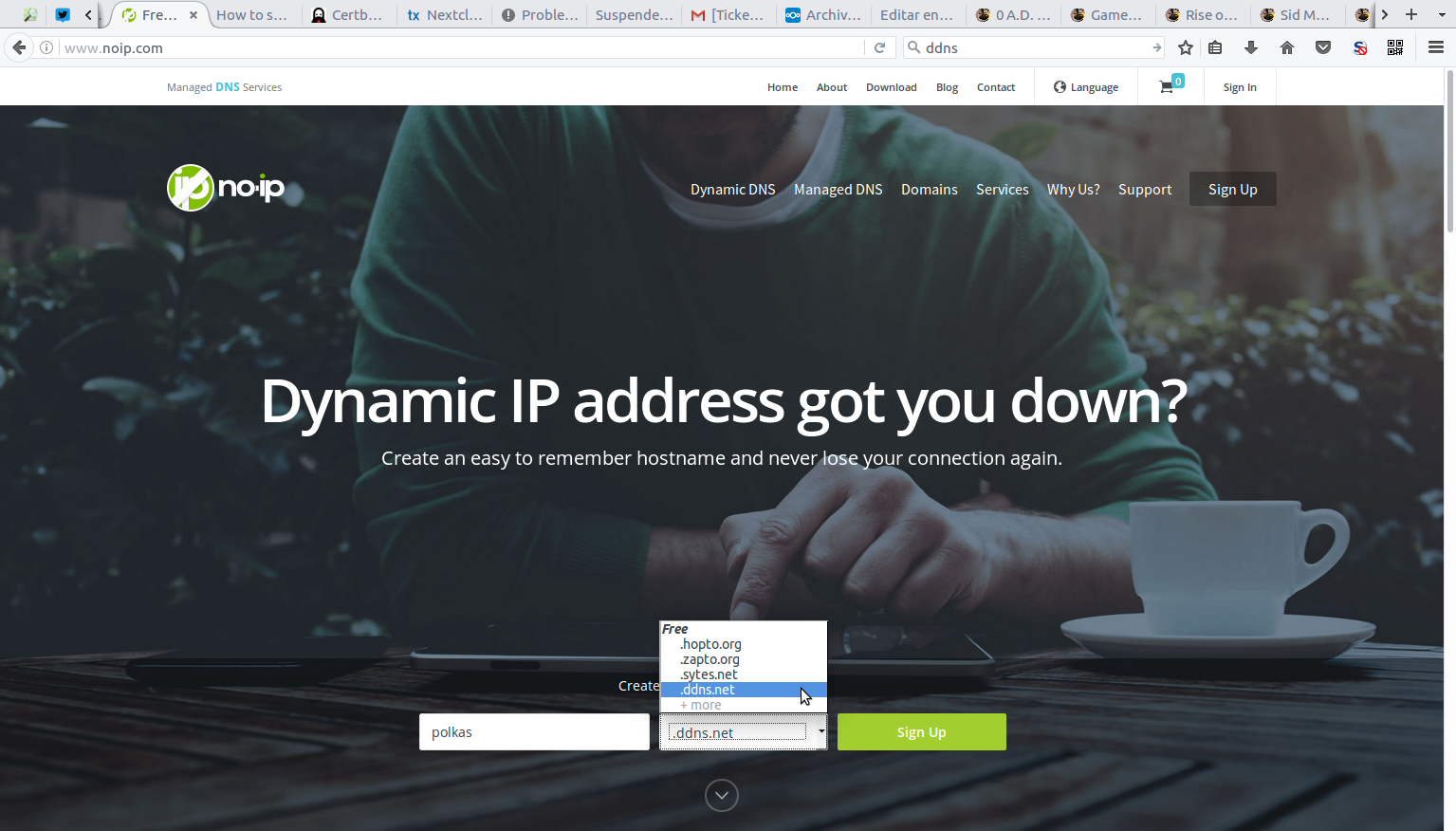
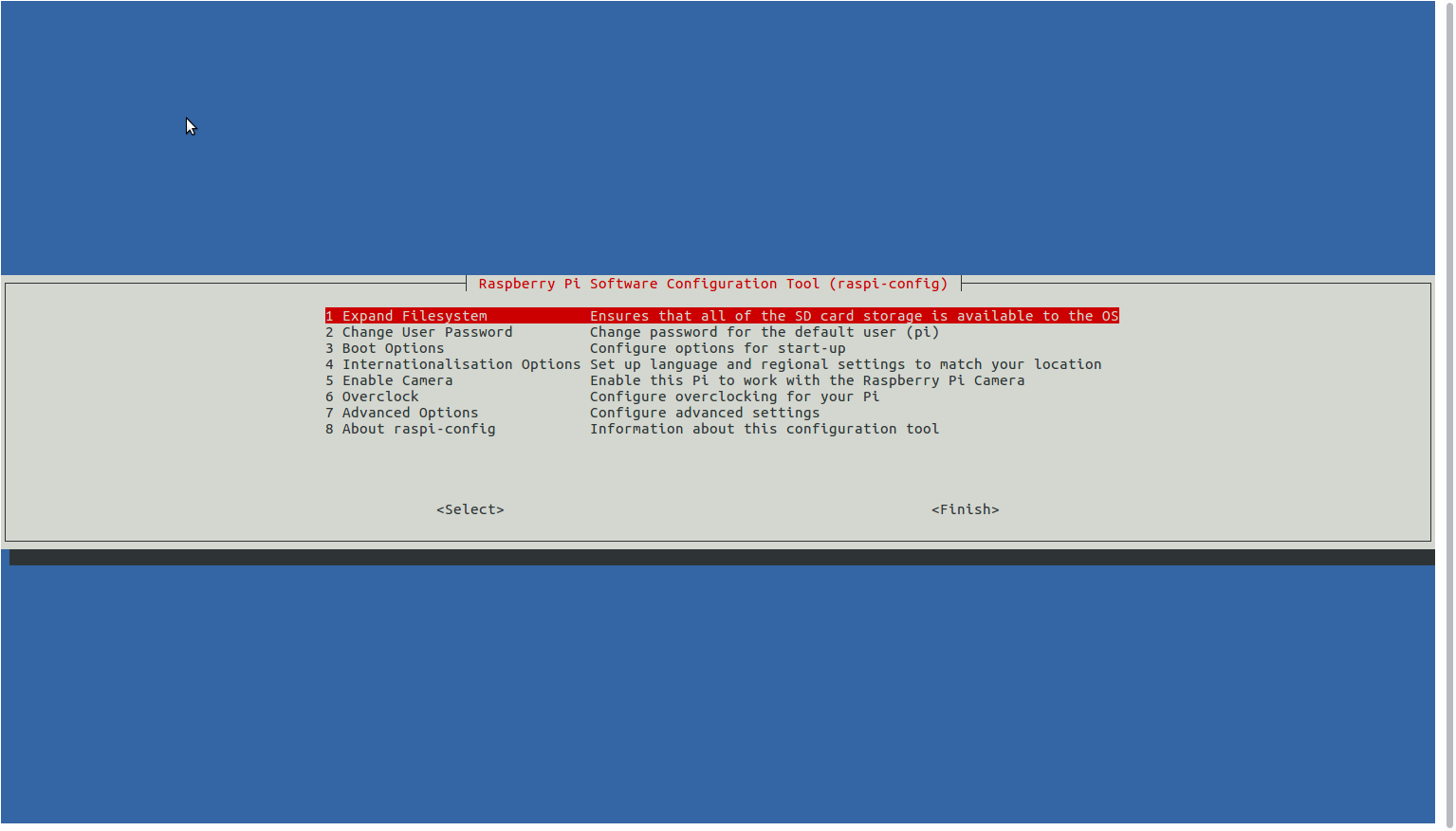
Cuando hemos hecho esto, podemos cambiar la configuración de la Raspberry. Enviamos la orden sudo raspi-config y nos aparece este menú.
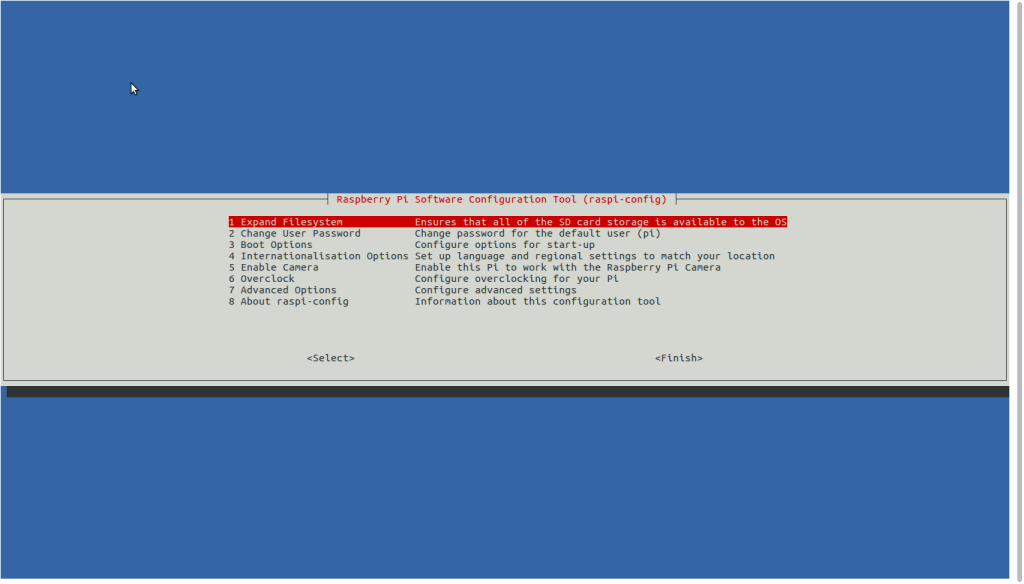
Hay varias opciones que nos van a interesar. Vamos con ellas en el orden en que aparecen en el menú, por el que nos movemos con las flechas arriba ya abajo. Para saltar a los botones de Aceptar o Cancelar, usamos el tabulador (la tecla que está a la izquierda de la Q).
1 Expand Filesystem
No debería hacer falta hacerlo al ser una instalación nueva, pero no pasa nada por hacerlo. Lo seleccionamos y nos avisa de que estará hecho después de reiniciar.
2 Change User Password
Podemos cambiar la contraseña por defecto del usuario «pi» porque es un agujero de seguridad tener una contraseña conocida. Sin embargo, es preferible crear otro usuario diferente y ponerle la contraseña que queramos. Lo veremos más adelante.
3 Boot Options
Esta opción es interesante si vamos a usar la Raspberry como ordenador de escritorio. Si no, no hace falta tocarla.
4 Internationalisation Options
Para poner la Raspberry en español este es el sitio adecuado. Las opciones que debemos seleccionar son estas:
I1 Change Locale
Buscamos la opción es_ES.UTF8 y la seleccionamos. Aceptamos y en la siguiente pantalla, en la que aparecen muchas menos opciones, la volvemos a seleccionar. Esperamos unos segundos a que se generen las locales.
I2 Change Timezone
Para no tener problemas, sobre todo, con el calendario de Nextcloud, tenemos que asegurarnos de que el servidor está en nuestra zona horaria. Escogemos nuestro continente y después la capital del país en el que estemos. En mi caso, Europa y Madrid.
I3 Change Keyboard Layout
El primer paso aquí no tan importante como el segundo. Si no encontramos nuestro modelo exacto de teclado o no lo sabemos, basta con dejar el «Generic 105 Intl». Lo importante es lo segundo. Seguramente saldrá una serie de opciones del idioma inglés, así que bajamos a «Other» y buscamos el idioma español. Una vez lo hemos localizado, la primera opción suele bastar, a no ser que tengamos algún teclado específico.
I4 Change Wifi Country
Yo no tuve problemas con la wifi antes de configurar esto, pero no sobra busca ES Spain y seleccionarlo, si vamos a conectar la Raspberry vía Wifi.
7 Advanced Options
De todas las opciones que tenemos aquí, solo comento las que nos pueden ayudar a que vaya mejor. Son estas:
A3 Memory Split
Si no tenemos escritorio instalado, la GPU (memoria gráfica) no necesita mucho, podemos reducir la cantidad que aparece a 16, que es el mínimo.
A4 SSH
Importantísimo. Sin más.
Según Wikipedia, SSH es el nombre de un protocolo y del programa que lo implementa, y sirve para acceder a máquinas remotas a través de una red.
Es decir, SSH sirve para “entrar” en un ordenador desde otro. Si está activado, podemos tener una línea de comandos en un ordenador diferente y trabajar en la Raspberry. En versiones anteriores, venía activado por defecto, pero desde hace un tiempo no es así. Este es el paso fundamental para poder usar la Raspberry sin necesidad de tenerla conectada a monitor y teclado., por lo que tendremos que seleccionar esta opción y activarla. Una vez que lo hemos hecho, podemos conectarnos a la Raspberry desde otro ordenador.
En Windows se puede usar PuTTY para ello y en Linux no hace falta instalar nada. Veamos:
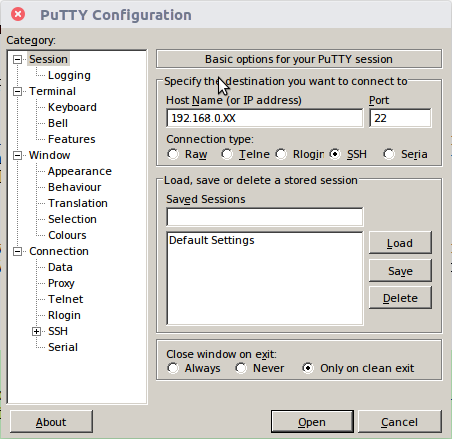
No hace falta instalar PuTTY, al abrir el archivo descargado se abre directamente esta ventana. En el campo “Host Name (or IP address)” tenemos que escribir lo que aparece en la imagen, cambiando las XX con unos números que estarán entre 0 y 255. Para saber exactamente qué número poner podríamos ir pr obando de uno en uno, pero hay una forma mucho más sencilla: cuando hayamos acabado de configurar la raspberry,,podemos escribir la orden ifconfig. Sale un montón de información pero lo que tenemos que buscar es la expresion inet address seguida de un número compuesto de cuatro cifras separadas por un punto y que sean las dos primeras esos 192.168. Si estamos conectados al router con un cable, estará en la sección eth0; si estamos usando wifi, estará seguramente en la sección wlan0.
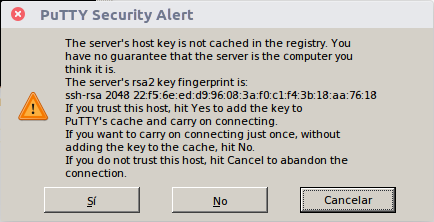
Si lo hemos hecho bien, nos aparecerá una alerta. Es normal, solo nos avisa de que nos estamos conectando a un ordenador nuevo y nunca hemos dicho a PuTTY que se fíe. Pulsar en sí hace que PuTTY, en adelante, confíe en nuestra Raspberry.
A continuación nos sale una pantalla nueva que nos pedirá el usuario de Raspberry PI OS (pi, si no lo cambiamos) y la contraseña (raspberry por defecto, ya cambiaremos esto). Al escribir la contraseña, como suele pasar en Linux, parece que no pasa nada, pero no es preocupante:
Al pulsar Intro, nos aparece el mismo mensaje que aparece en el monitor de la Raspberry al arrancar, lo que nos confima que esa pantalla “es” la Raspberry.
En Ubuntu y otros Linux, abrimos un terminal (CTRL+ALT+T o abrimos el tablero y escribimos “terminal”). Para usar SSH, la forma es sencilla:
ssh pi@192.168.XX.XX
Igual que en PuTTY, cambiamos los dos últimos números por el resultado de ifconfig:
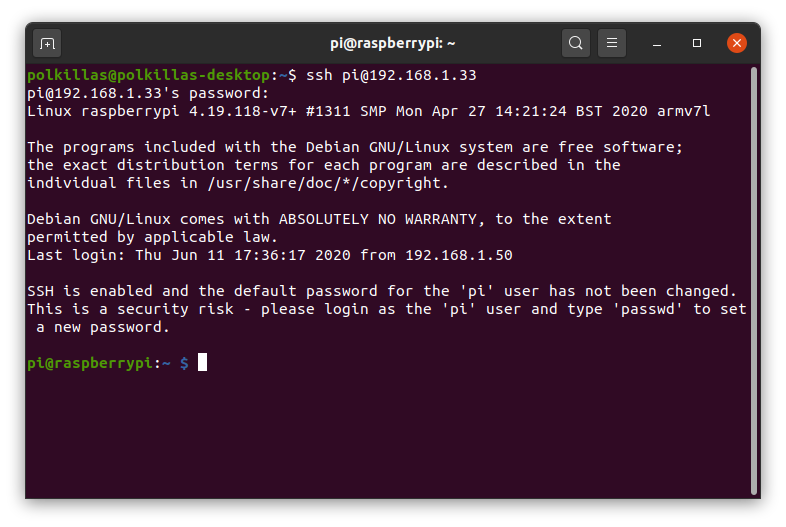
¡Voilà! A partir de este momento no nos hace falta tener un monitor conectado a la Raspberry mientras haya conexión a internet.
A0 Update
Sirve para actualizar el mismo programa raspi-config. Lo más probable es que no haya actualizaciones.
Con esto tenemos configurada nuestra Raspberry y podemos empezar a instalar los programas que vamos a necesitar para que funcione bien nuestro Nextcloud.
La penúltima cosa que podemos hacer es fijar la IP de la Raspberry para no tener problemas de conexión. En mi experiencia no me ha pasado porque no he desconectado nunca el cable de red que une la Raspberry con el router. Pero si este fuera el caso y hubiera algún problema con la conexión, podría ser porque se ha asignado una IP diferente a la Raspberry. En este caso, recomiendo acudir a Raspberry para torpes, donde manuti tiene 3 entradas que nos pueden ser útiles:
Por último, una cosa que me parece muy recomendable es cambiar el usuario por defecto, (pi), por otro diferente y la contraseña de root. Esto hace que sea más difícil que un posible atacante pueda entrar en la Raspberry, pues no solo tiene que adivinar la contraseña sino también el usuario. Para ello seguiremos algo de un tutorial de Juan Jose Ramirez Lama en su blog juaramir.com y una página vieja pero aún muy útil, Principiante Linux.
Para cambiar la contraseña del superadministrador, escribimos la siguiente orden:
sudo passwd
Nos pide que escribamos la nueva contraseña y que la repitamos, por si acaso nos hemos equivocado al escribirla. Después iniciamos sesión como administrador con el comando sudo su y metemos la contraseña que acabamos de cambiar si nos la pide.
Para cambiar el usuario “pi” debemos crear un usuario nuevo con la siguiente orden:
adduser USUARIONUEVO, sustituyendo las mayúsculas por el nombre que queramos darle al usuario. Como estamos como administrador, no necesitamos sudo delante.
Nos pide que escribamos dos veces la contraseña del nuevo usuario y nos hace una serie de preguntas que no hace falta responder, podemos pulsar Intro en cada una.
A continuación podemos modificar el usuario para darle derechos de administrador. Con la orden groups pi veremos los grupos a los que pertenece ese usuario, y podemos usar groups USUARIONUEVO para comprobarlo en el nuevo. Para darle permisos, hay que dar la siguiente orden:
usermod -G adm,dialout,cdrom,audio,video,plugdev,games,users,input,netdev,spi,i2c,gpio,sudo USUARIONUEVO
De la ristra de palabras entre comas, lo más importante para nuestros objetivos es “sudo”. El resto da otros derechos que para otros usos de la Raspberry serán necesarios. Podemos comprobar que lo hemos hecho bien volviendo a ejecutar groups USUARIONUEVO, y veremos que ya tiene los mismos derechos que “pi”.
Cerramos la sesión de «root» escribiendo exit y la sesión de «pi» volviendo a escribir lo mismo, y volvemos a entrar, ahora con el nuevo usuario. Ahora ya podemos eliminar el usuario pi con la orden sudo userdel -r pi.








Comentarios recientes