
Esta entrada supera los límites de las entradas anteriores. Hasta ahora, todo lo que hemos hecho en Nextcloud lo hemos podido hacer con nuestra Raspberrry Pi, pero esta característica supera sus capacidades.
La búsqueda de texto completo es una de las cosas más interesantes que puede hacer Nextcloud. Se trata de buscar texto. [Abucheos ante el chiste malo].
A ver, al instalar Nextcloud nos aparece en la barra de arriba una lupa con la que podemos buscar archivos, y en diferentes apps podemos buscar en sus contenidos (marcadores, RSS, etc.). Pero solo podemos buscar en los nombres de los archivos. Y cuando recordamos una frase del archivo pero no su nombre, ¿qué hacemos? Por ejemplo, más de una vez me ha pasado, preparando un examen, querer encontrar aquel examen en el que puse un texto concreto, pero no recuerdo en qué examen fue. Si busco «examen» me van a salir todos los exámenes que he ido preparando a lo largo del tiempo, pero no puedo buscar por las palabras del texto, con lo que me será muy difícil encontrar ese examen en concreto.
Sin embargo, con el ecosistema de apps de Búsqueda de Texto Completo, la lupa sí va a poder buscar en el contenido de los archivos. En el ejemplo, si busco «Ondas do mar de Vigo», no me buscará solo archivos que se llamen así (probablemente ninguno), sino que encontrará todos los archivos que contengan ese texto: una antología de textos de la Edad Media, un powerpoint en el que puse el poema y, por fin, el examen donde puse ese texto.
Lo malo de la búsqueda de texto completo es que es una función que exige mucho al servidor, está basada en Java y en mi instalación, que todavía no he completado, utiliza 1 Gb de memoria RAM. Y eso es más que la memoria disponible en cualquier modelo de Raspberry. Por lo tanto, he tenido que instalarlo en otro ordenador. Para estas pruebas estoy utilizando mi ordenador de sobremesa, aunque mi intención es dedicar mi viejo portátil Acer a esto.
Bueno, al lío. La instalación de la búsqueda de texto completo es la tarea más complicada que he conseguido hasta ahora en Nextcloud. Hace unos años, recién bifurcado Nextcloud de Owncloud, conseguí instalar la versión que había entonces, pero estaba basada en una tecnología diferente (Apache Solr) y cuando cambiaron a la actual (ElasticSearch) me superó la tarea y de vez en cuando he echado un vistazo para intentar encontrar qué hacía mal, pero hasta hoy 20 de marzo, después de haber sido padre, no he conseguido encontrar lo que hacía mal al instalar ElasticSearch.
Los pasos que he dado están sacados de la documentación oficial de ElasticSearch y de un blog que enlazaré después.
Lo primero es instalar un par de paquetes que permiten seguir las instrucciones, entre ellos la versión abierta de Java. Ojo, no en la Raspberry sino en el ordenador más potente en el que vamos a instalar ElasticSearch:
sudo apt-get install apt-transport-https curl net-tools openjdk-8-jre
A continuación añadimos el repositorio a APT:
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
Descargamos e instalamos la firma GPG para que apt no dé errores:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Actualizamos la información e instalamos ElasticSearch y Kibana. No tengo ni idea de qué es Kibana, esto es software complejo y su estructura me supera, pero parece que es necesdario.
sudo apt-get update && sudo apt-get install elasticsearch kibana
A continuación hay que instalar en ElasticSearch el «ingestment-plugin», que creo haber entendido se encarga de introducir en la base de datos lo que vamos a buscar después. Para ello vamos al directorio:
cd /usr/share/elasticsearch/bin
y ejecutamos esta orden:
sudo ./elasticsearch-plugin install ingest-attachment
Ahora podemos arrancar los servicios de ElasticSearch y Kibana y configurar que se ejecuten siempre al arrancar el ordenador:
sudo systemctl start elasticsearch
sudo systemctl enable elasticsearch
sudo systemctl start kibana
sudo systemctl enable kibana
ElasticSearch está configurado para instalaciones inmensas distribuidas en varios servidores, de tal forma que cada conjunto es un clúster que se puede distribuir en nodos. Ahora tenemos que configurar nuestra instancia con el nombre del clúster y del nodo que queramos, aunque nuestra instancia sea muy humilde. Editamos el archivo de configuración con
sudo nano /etc/elasticsearch/elasticsearch.yml
y buscamos cluster-name (recuerda que en Nano el atajo de teclado para buscar es CTRL+W) y node-name. Descomentamos estas dos líneas eliminando la almohadilla (#) del principio y ponemos como nombre del clúster y del nodo lo que queramos:
cluster.name: nextcloud
node.name: nodonube
Por ejemplo. Guardamos y salimos, aunque después volveremos a este archivo, porque necesitamos un dato adicional. con el que llegamos ael paso que me faltaba. Por defecto, ElasticSearch está configurado para escuchar solo peticiones del ordenador/servidor en el que esté instalado. Puesto que en nuestro caso las peticiones las va a hacer la Raspberry, tenemos que cambiar esto. Para ello, podemos seguir los siguientes pasos.
En primer lugar, debemos descubrir cuál es la dirección IP del ordenador en el que hemos instalado ElasticSearch. Para ello ejecutamos ifconfig (que viene del paquete net-tools que hemos instalado al principio).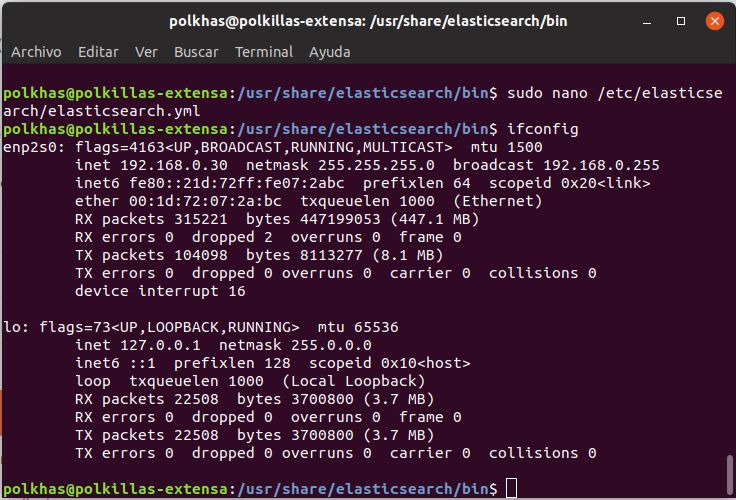
Dependiendo de si está conectado por wifi o por cable, cambiará. En mi ejemplo, está conectado al router por cable Ethernet y hay que mirar en la sección enp2s0, el apartido inet.
Con esta dirección IP de cuatro cifras, volvemos a editar la configuración de Elasticsearch con sudo nano /etc/elasticsearch/elasticsearch.yml. Buscamos el apartado network.host, lo descomentamos borrando la almohadilla y cambiamos la dirección por la que acabamos de encontrar. También añadimos una nueva línea para indicar que Elasticsearch no solo escuche a su propio ordenador sino que acepte peticiones de otros servidores en la red porque, si no, la Raspberry no podrá utilizarlo. Lo hacemos con network.bind_host: 0. Debe quedar así:
network.host: 192.168.0.XXX
network.bind_host: 0
Guardamos y salimos. Con esto ya tenemos configurado Elasticsearch. Ahora tenemos que ir a Nextcloud para configurar las apps de búsqueda.
Lo primero es instalarlas. Las que son obligatorias son tres: «Full text search», «Full text search – Elasticsearch Platform» y «Full text search – Files». Como en alguna ocasión anterior, cuando llegue la siguiente versión de Nextcloud, estos nombres deberían estar ya traducidos al español, gracias a un servidor. También podemos instalar el resto, para buscar en los marcadores (Bookmarks) y algo más complejo: extraer las palabras de los archivos en los que hay texto guardado como imagen (muchos pdf, por ejemplo, con «OCR».
Pulsamos «Descargar y activar» para cada app que queramos instalar. Como se puede ver, yo me he instalado todas, para probarlas.
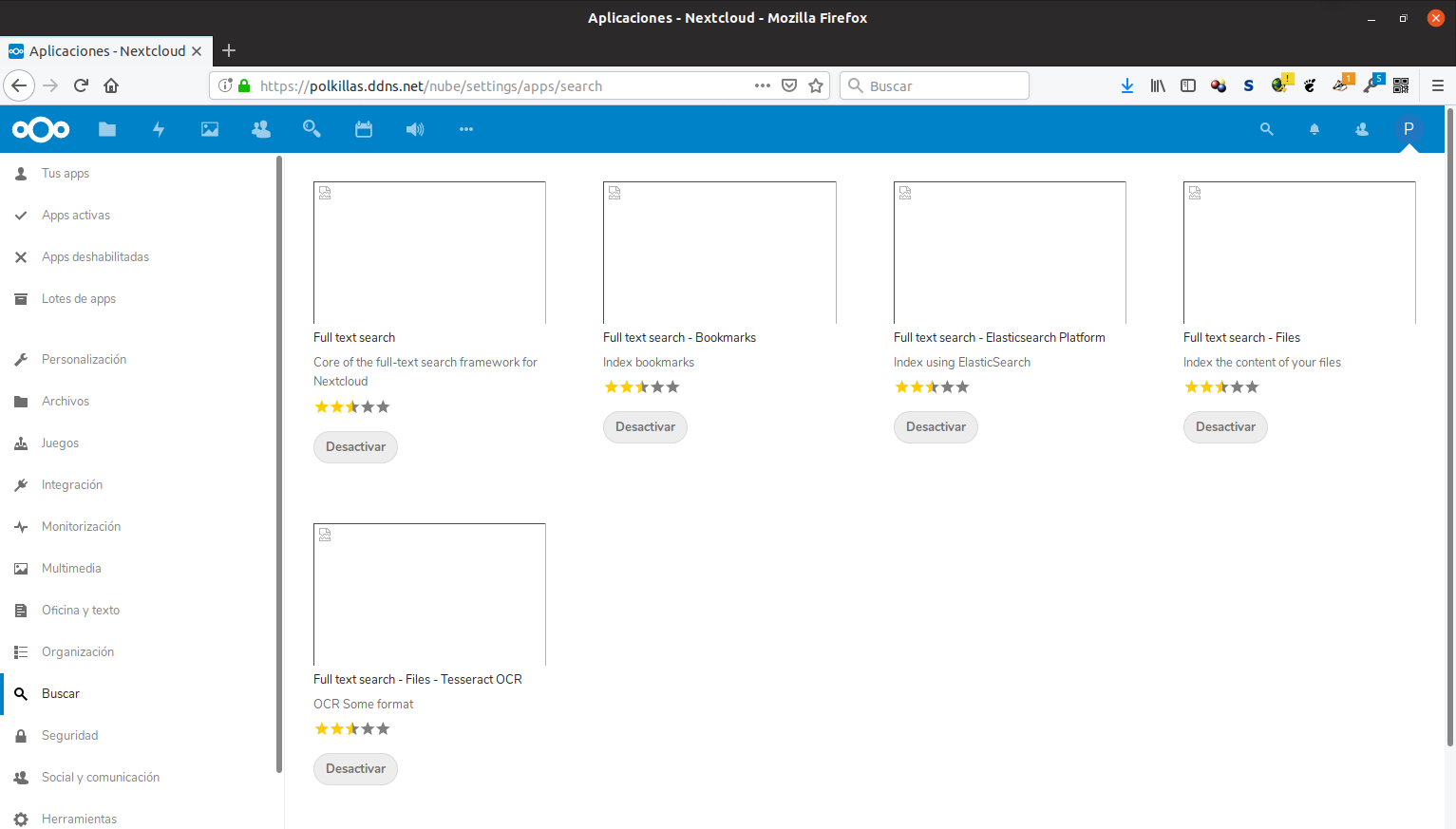
Una vez instalados, debemos configurarlas. En el menú de configuración vamos al apartado de Administración y seleccionamos «Búsqueda de texto completo».

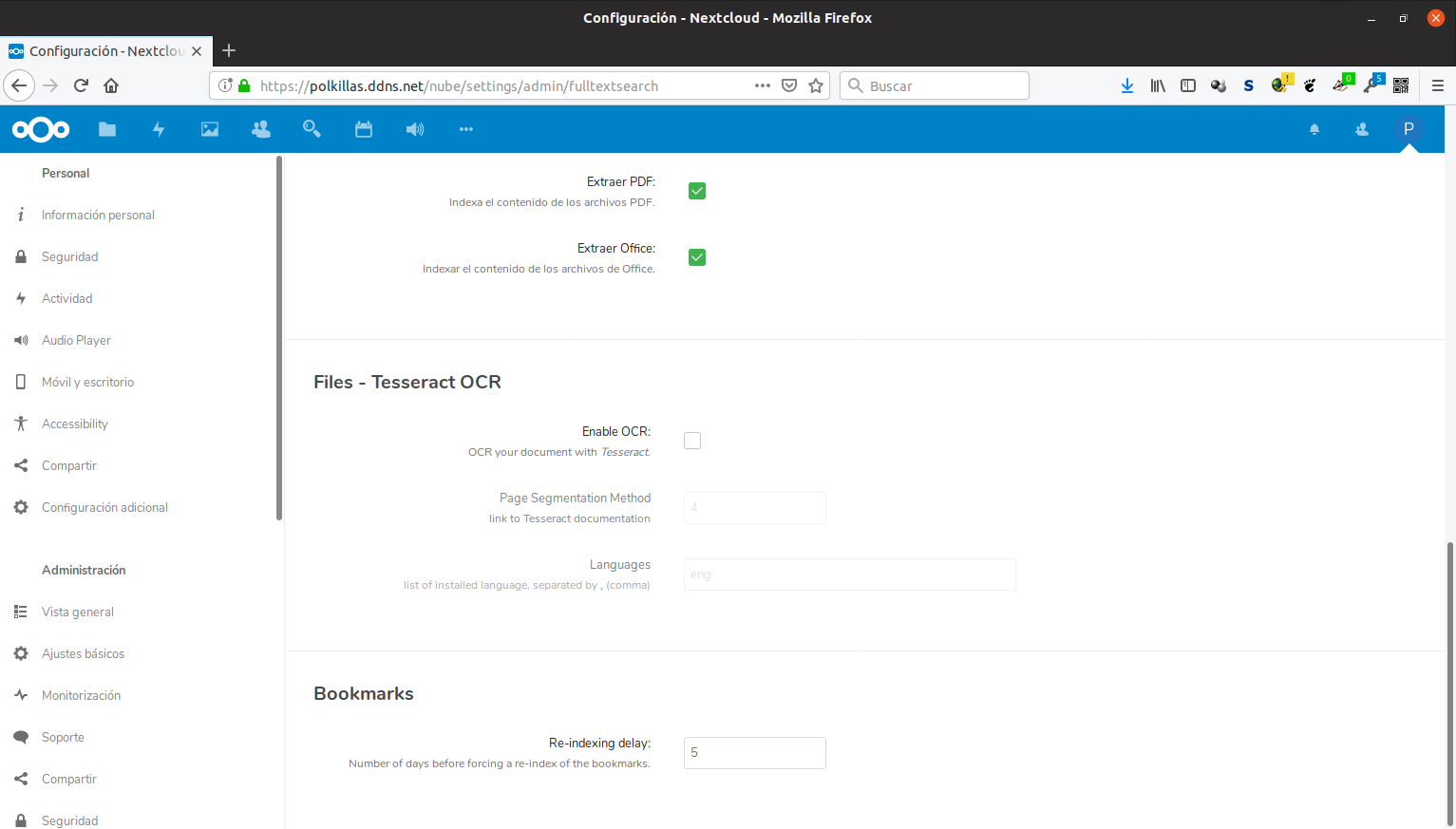
En «General», indicamos como plataforma Elasticsearch. Se supone que en un futuro habrá otras plataformas, incluyendo la que se usaba en versiones anteriores de Nextcloud (Solr) pero por ahora solo hay una. También marcamos la casilla.
En Elastic Search señalamos la dirección del servidor donde está instalado y añadimos el puerto (el estándar, como se ve, es el 9200, aunque se puede cambiar en la configuración de Elasticsearch). Le damos un nombre al índice y dejamos el tokenizador estándar, habría que cambiarlo para idiomas que sean más complejos.
En el resto de opciones dejo lo que he puesto yo, pero dependerá de lo que cada uno quiera conseguir con la búsqueda.
Me queda pendiente probar el OCR, pero por ahora estoy satisfecho con haber sido capaz de instalar y configurar esto. Seguiremos probando cosillas de Nextcloud cuando salga la inminente versión 16.
Comentarios recientes